贪心策略
LLM在生成预测Token时,总是选择概率最大的Token。这种方法容易导致模型倾向于生成重复的内容
Beam Search
Beam Search拥有更加宽容的采样策略,并且贪心策略就是在Beam Size = 1的Beam Search特殊情况。
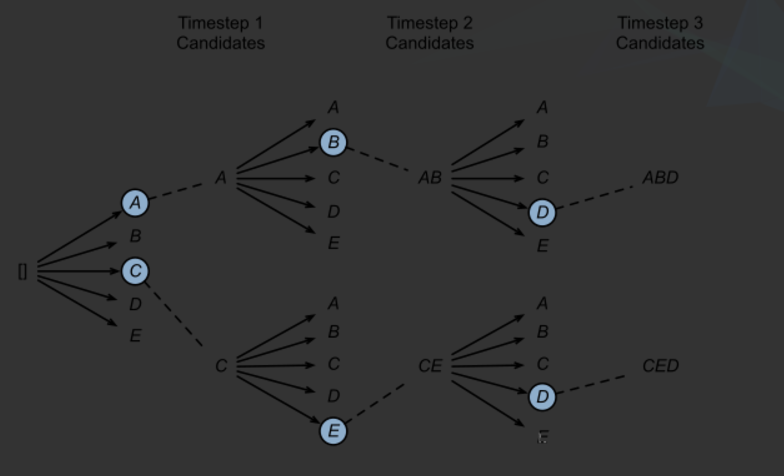
在LLM生成下一个Token时,我们保留概率最大的Beam Size个token。如上图中,beam Size = 2,所以保留概率最大的2个token (A,C)。当继续预测下下一个token的时候,分别从当前的序列(A,C)继续生成,每个序列后续可以生成5种可能,一共就是10种序列可能(AA,AB,AC,AD,AE,CA,CB,CC,CD,CE),我们选择保留概率最大的2种可能得序列。
以此类推,每次都只保留概率最大的Beam Size个可能得token序列。
Beam Search在一定程度上引入了更加丰富的多样性,缓解模型陷入局部最优解,但是依然有一定概率导致模型生成重复的内容。
Top-K sampling
LLM在生成下一个token的时候,只保留概率最大的k个token,然后在这k个token中进行随机采样。
这种方式丢弃了生成概率过低的token,又能够极大地增加生成的多样性。
Temperature
温度参数主要用于sigmoid的归一化函数中,通过设置参数来调整归一化之后分布的平滑性。
效果:
-
:分布变得更平坦,增加随机性。低概率词更有可能被采样。
-
:分布变得更尖锐,模型更倾向于选择高概率词。
-
:不调整分布,按原始概率采样。
优点:
- 可以控制生成文本的创造性和多样性。
缺点:
-
温度过高可能导致无意义输出。
-
温度过低可能导致重复或单一性。