KV Cache的不足
我们知道,LLM通过计算当前Token和过往所有Token的QK值,并与V向量做加权求和,以此来预测下一个Token。在计算加权求和的过程中,可以发现KV的计算是冗余重复的,因此可以通过KV Cache来缓存中间结果,大大提升推理速度。
然而,KV Cache在显存利用率上存在以下不足:
-
预分配显存,但是利用不到:由于LLM的输出长度并非固定,有的问题回答长,有的问题回答短,如果预分配最大长度的显存,在LLM输出短的回复时造成了大量的浪费
-
预分配显存,但是尚未利用:在一次请求A中,预分配了显存等待KV Cache填充,但是此时另外一个B请求也由LLM生成回答,并且只会回复很短的内容,那么此时却无法利用请求A预分配的显存(反正此时A预分配的显存暂时又用不到)
-
显存碎片问题:即使所有请求生成长度完全一样,但是由于Prompt的长度不同,每次预分配的KV Cache大小也不同,当一个请求生成完毕释放显存,但是下一个请求的Prompt长度大于这次请求的Prompt的长度,因此无法放入刚刚被释放的显存中。
Page Attention
内存碎片问题在操作系统中是常见的问题,不同的进程所需要的内存大小不同,释放时机不同,这和KV Cache遇到的问题如出一辙。操作系统采用了 Page 和 虚拟内存 的方法来解决进程内存分配问题,vLLM便是借鉴了这种技术提出了Page Attention。
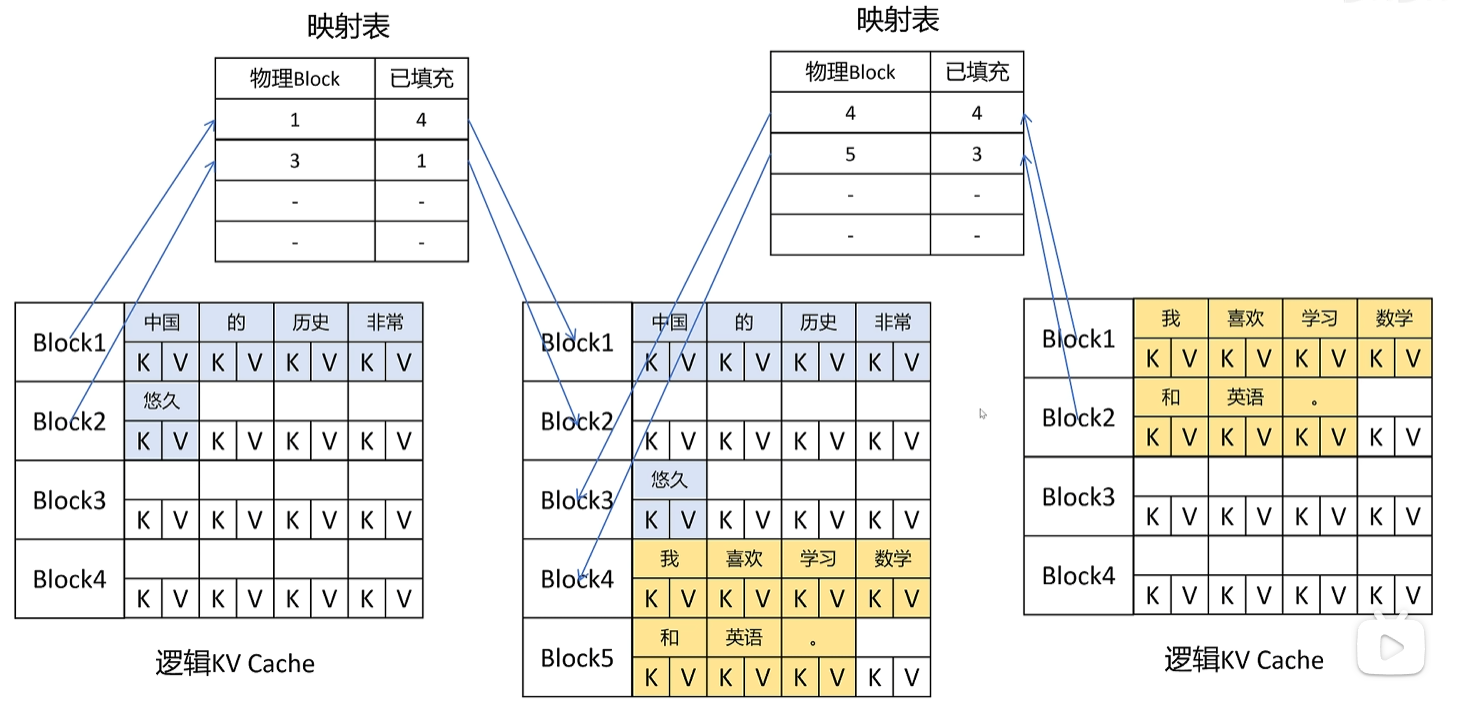
在OS中,内存被划分为大小为的多个page,每个进程拥有虚拟申请可以申请不同大小的虚拟内存,虚拟内存和物理内存通过映射表来关联。
类似地,vLLM将显存划分为 KV Block,例如 4个Token的 KV Cache 大小为一个KV Block,每次请求都可以申请虚拟显存,按照KV Block进行分配,虚拟显存和物理显存由映射表关联。这种方式减少了显存碎片,大大提高了显存利用率。最终效果,vLLM一般可以将显存利用率从20%~40%提升到了96%
Shared KV blocks
当多个请求共享一个Prompt,那么为什么不将这个Prompt的KV Block共享呢?这又可以减少显存占用,提高吞吐量。