LLM 单机训练的瓶颈
-
LLM越来越大,单机显存不足
-
训练速度不足
分布式并行训练方向
LLM可以从三个角度来进行分布式拆分:
-
数据并行(应用最广)
-
模型并行/流水线并行/层间并行(不同叫法)
-
张量并行/层内并行(不同叫法)
甚至可以三种并行方式同时应用,最大化利用显存和加速训练。
数据并行
将原始数据分割成不同的不想交子集,不同计算设备分别处理子训练集。由于每个计算设备都独立存储着完整的模型副本,因此各个模型反向传播得到的梯度需要汇总求平均。Transformer架构的每个算子的前后向传播都只依赖于单个数据,而不是训练批次,所以数据无论怎么划分实现并行不会影响梯度的计算逻辑。
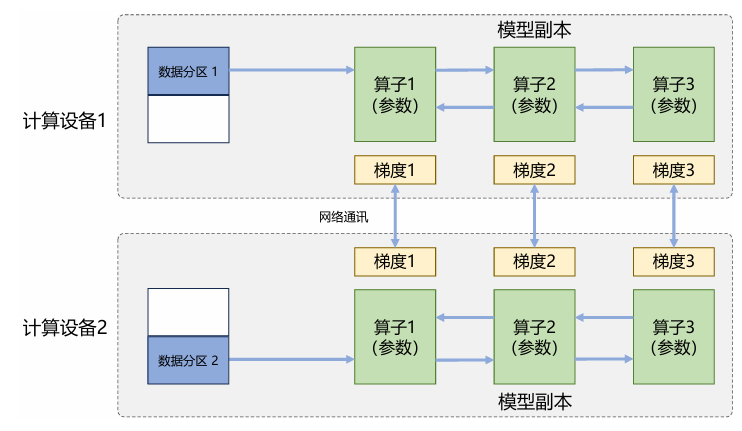
这种并行方式的各个计算设备不涉及同步问题,加速比最高,但是每个设备上都需要保留完整的模型参数,所以训练大型LLM依旧不够实用。
通讯量分析:
传入阶段:
流水线并行/层间并行/模型并行
如果单个GPU无法存储整个模型的参数,不如将模型也拆了吧。不同计算设备存储着模型的不同层,可以有效减少单个设备的模型存储占用空间。
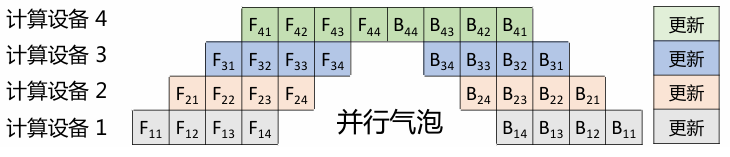
流水线并行的思路来源于CPU,那么同样也会有CPU中遇到的并行气泡问题。在热身阶段,下游计算设备需要等待上游计算设备的结果,这种等待造成的资源浪费就是并行气泡。
仔细分析上图,可以发现在计算设备4反向传播 , 就无法进行前向传播 (图中没有), 这就是单个计算设备由于同时负责前向和后向传播导致的并行气泡。
Megatron中提出了将前向和后向分离的解决方案,减少了并行气泡,但是流程有些看不懂,这里挖个坑。
张量并行
张量并行的思路是拆分单个算子,也就是层内拆分与并行。由于算子之间千差万别,需要单独分析拆分可行性和提供实现方案,比较头疼,并没有流水线并行那么通用。
仅仅分析在Transformer架构中,算子主要包括:嵌入式表示Embedding,矩阵乘MatMul,交叉熵损失Cross Entropy Loss
如果想要拆分Embedding,就只能沿着word_size的维度切割并分放到不同计算设备中。
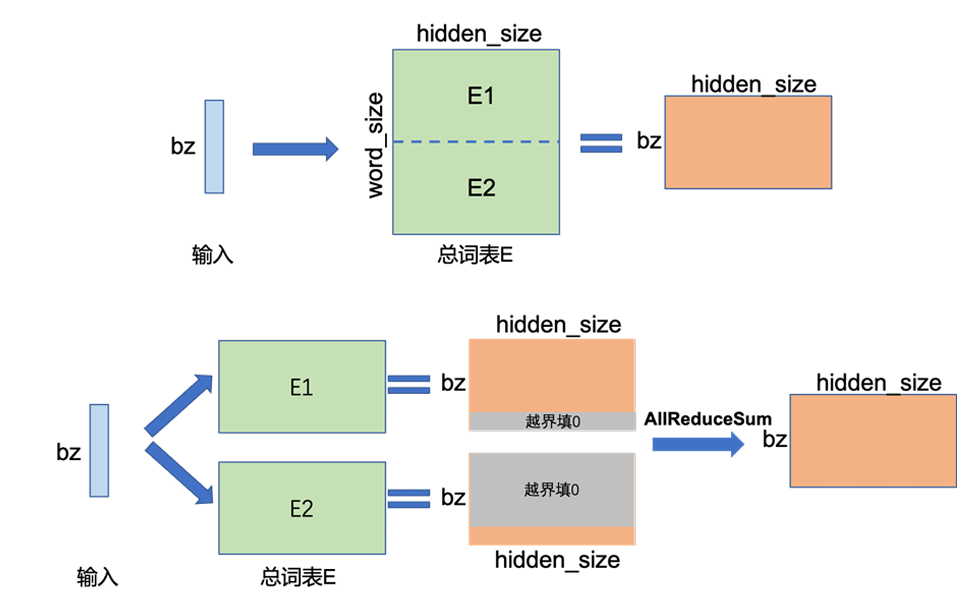
整个Embedding的大小如果为, 采用FP32表示方式则占用空间 , 反向传播的梯度同样占用, 要是使用的是Adam类优化器,一阶动量和二阶动量又各占 , 总共就占用了 。如果沿着word_size维度拆分为两个大小相同的Embedding, 那单个设备仅占用, 比较划算。
由于Embedding被分拆到两个不同的设备中,那么使用起来就麻烦了,需要在各个设备中处理然后汇总,也就是图中的AllReduceSum.
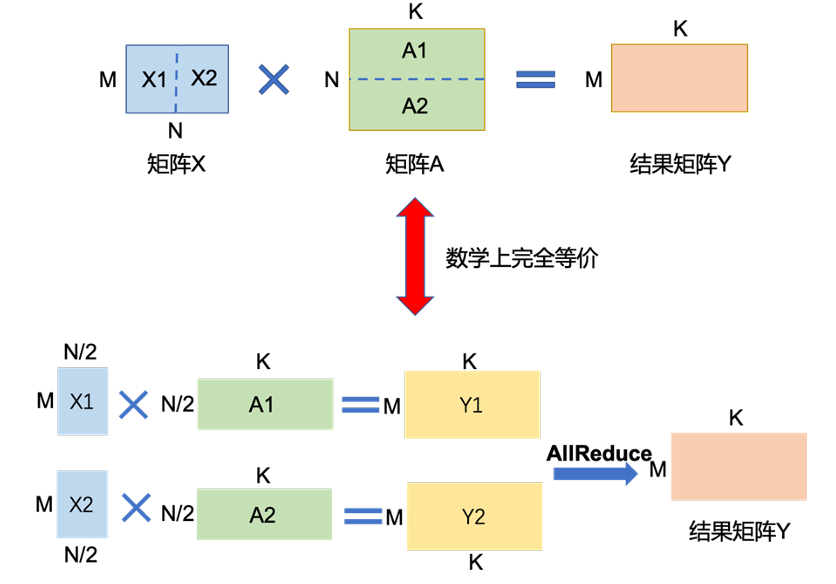
如果想要拆分矩阵乘法MatMul , 则只能按照线性代数的分块矩阵的方法解决(分块矩阵这种知识居然真的有用武之地:))
分布式通讯架构
上述的三种方式仅仅是分析可以从哪些角度来分割数据或者模型,然后通过通讯的方式来汇总计算结果,这里更加深入了解具体的分布式通讯方式中的去中心化架构。
分布式通讯原语:
-
Scatter:主节点将数据进行划分并散布至其他指定的节点
-
BroadCast:主节点把自身的数据发送到集群中的其他节点
-
Reduce:是一系列简单运算操作的统称,是将不同节点上的计算结果进行聚合
-
AllReduce:在所有的节点上都应用同样的Reduce操作
-
Gather:将多个节点上的数据收集到单个节点上,Gather可以理解为反向的Scatter
-
All Gather:将所有节点上收集其他所有节点上的数据
-
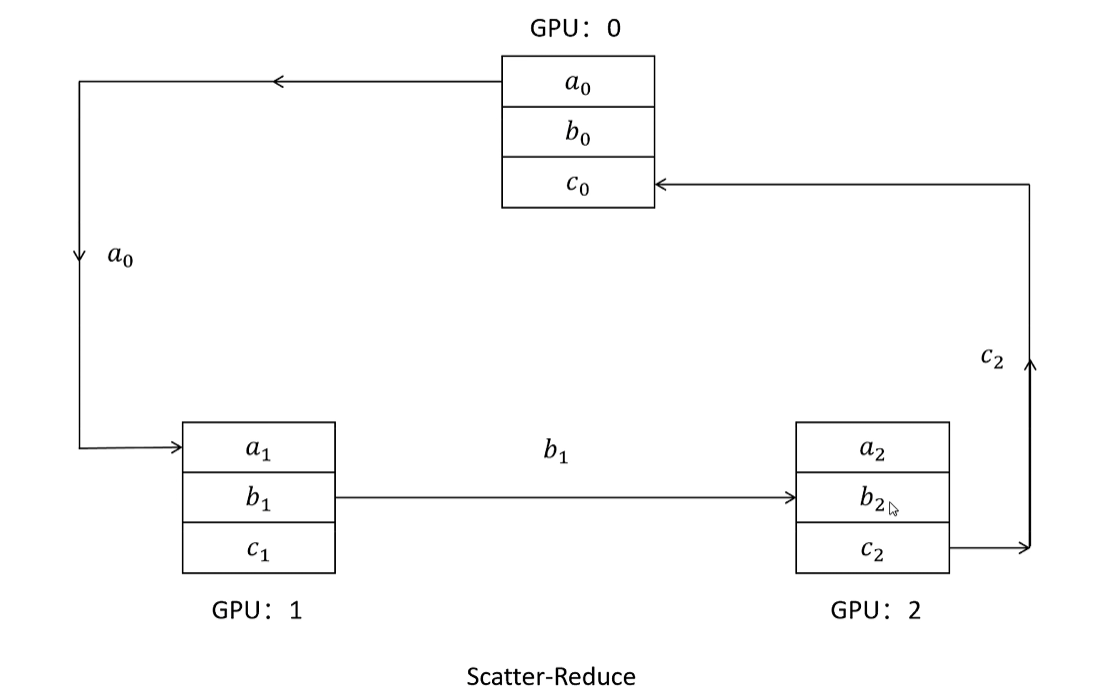
Reduce Scatter:将每个节点中的张量切分为多个块,每个块分配给不同的节点
去中心化分布式架构:
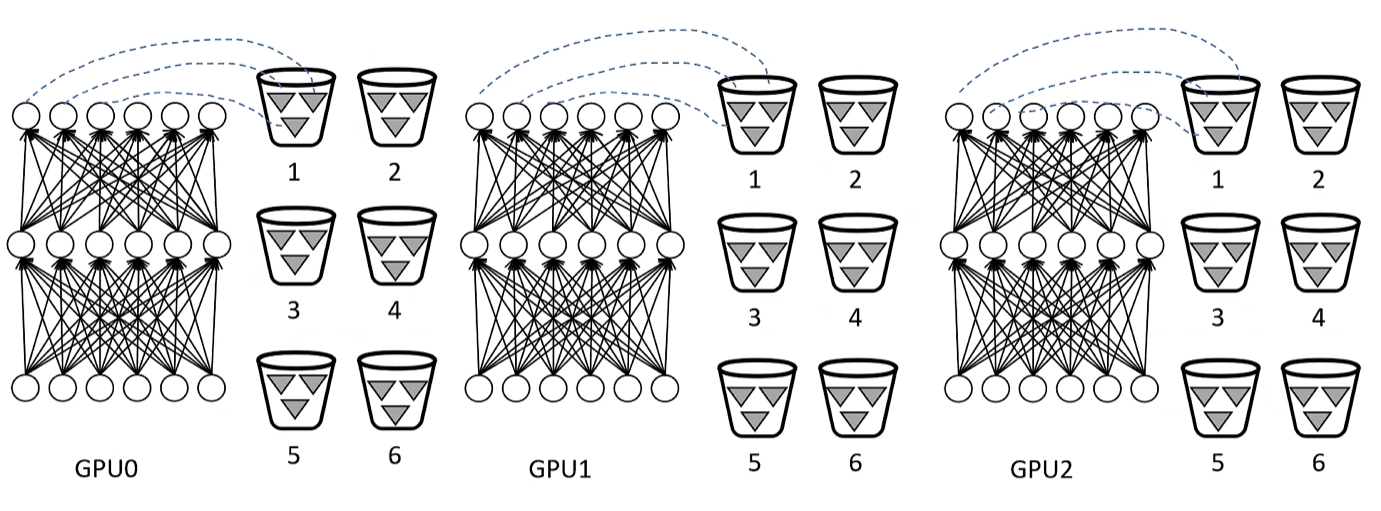
分布式通信加速策略:
通过设置参数监听器,将参数梯度存储在桶中,大大提升梯度参数通讯速度(和操作系统中buffer IO一个道理)
工业实现
NVIDIA开源的Megatron和Microsoft开源的DeepSpeed都提供了分布式训练的能力,前者更加侧重于张量并行,后者更加侧重于数据并行和模型并行。
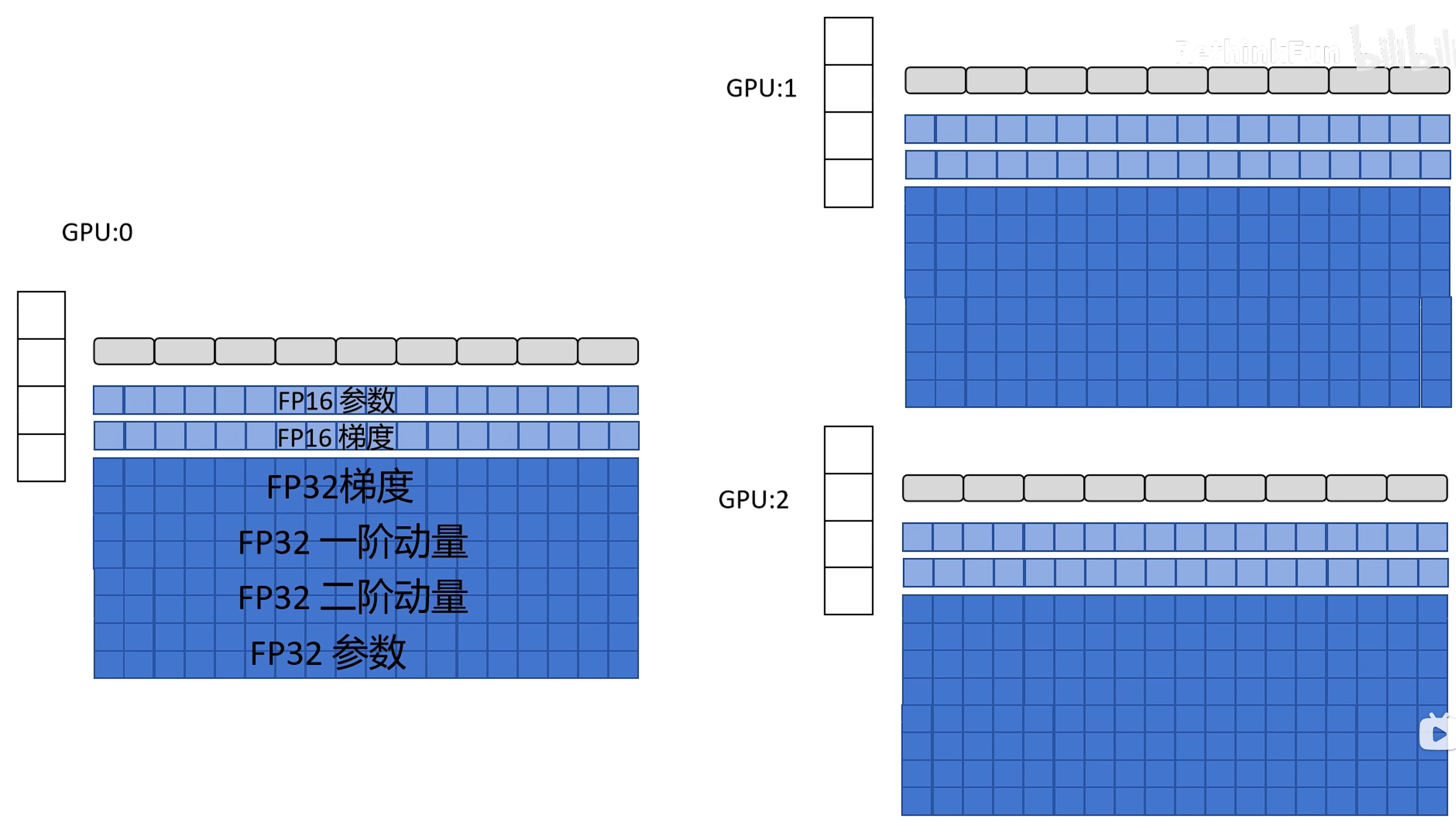
如图,在混合精度和Adam的条件下,显存占用分为:模型的参数的FP16表示、模型梯度的FP16表示、模型全精度FP32参数、全精度FP32的梯度/一阶动量/二阶动量。
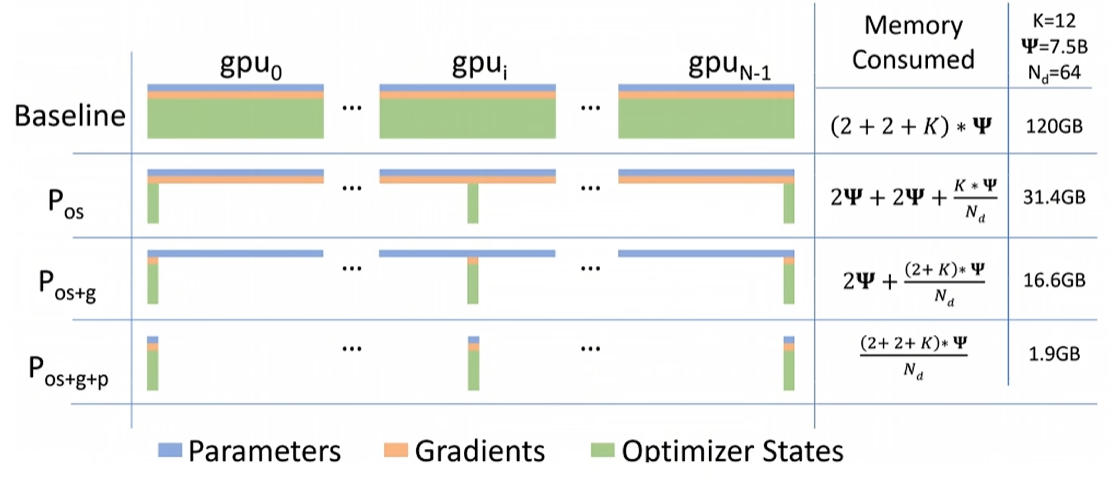
DeepSpeed提供了三种级别的参数冗余消除能力,不同级别对显存的优化如下图:
DeepSpeed Zero1
零优化器参数冗余: 每个计算设备只保留自己负责的模型参数部分的优化器参数
DeepSpeed Zero2
零优化器参数+梯度冗余:既然每个设备只更新自己负责的模型参数,那么也就只需要保留自己负责的模型梯度。
在反向传播时,和计算出梯度之后,立刻发送给 并释放掉显存,只有才能计算总的模型梯度平均值。后续更新更靠前的模型参数梯度的过程也类似。
DeepSpeed Zero3
零优化器参数+梯度+模型参数冗余:模型参数也按照不同计算设备划分。
举个栗子,在进行前向传播时,和都没有第一层的参数(这里是FP16的模型参数),就只能让广播参数发送给它俩,计算完之后立刻释放显存。