Redis基本原理
Redis底层手搓了很多数据结构,更加适合Redis的应用场景,提高了高性能和低存储消耗
String数据结构
Redis的String设计结构和其他地方(JAVA、C++)的不太一样,其独特的设计保证了高性能和低存储消耗。
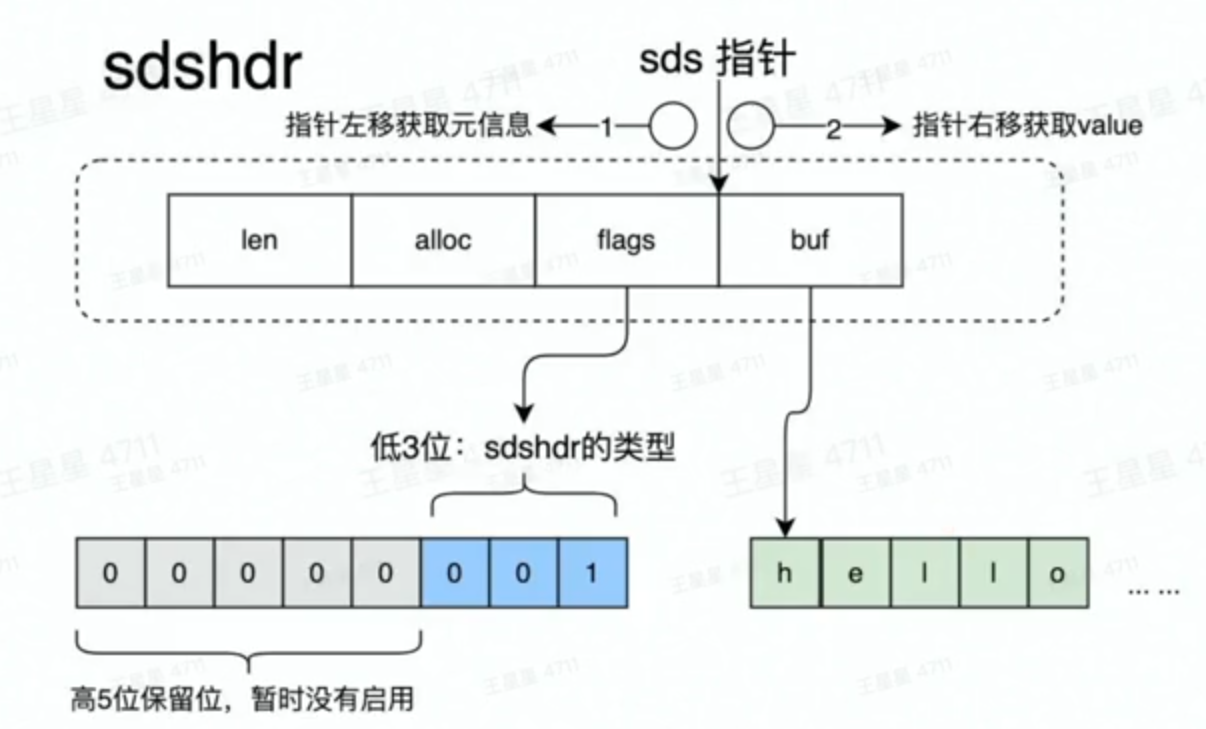
如图所示,Redis中的String数据结构由len、alloc、flags、buf组成。key的指针指向这flags和buf中间,保证了快速的读出性能。在获取一个key-String 时,只需要把指针向左移动数位便能知道数据的类型, 分配的空间大小,所使用的空间大小,往右移动数位就能直接得到String的具体内容。
QuickList
我们常见的List是单向链表+链表中只能存储一个元素,Redis中提供了升级版的双向链表+链表中存储多个元素的QuickList.
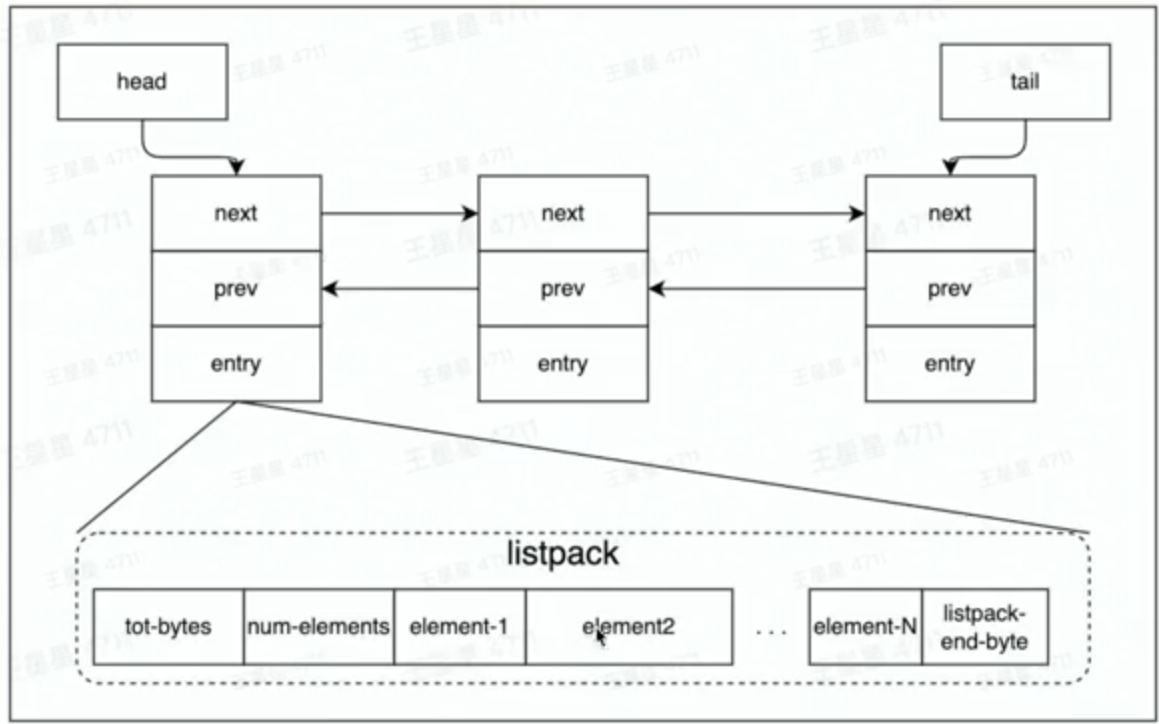
如图中所示,entry存储可以存储多个元素,统一打包叫做listpack,其内部组成为:
-
tot-bytes: listpack所占据的整个空间字节大小
-
num_elements: 存储的元素的个数
-
element1~n:存储的n个元素
-
listpack end-byte: listpack结束的位置
Hash
Hash是Redis本质的思路,在所有的编程语言中都有实现,非常常见。Hash的元素会被存储到不同的槽位,如果不同元素分配到同一个操作就会形成链表,链表过长就会形成红黑树,这个过程无需多言。
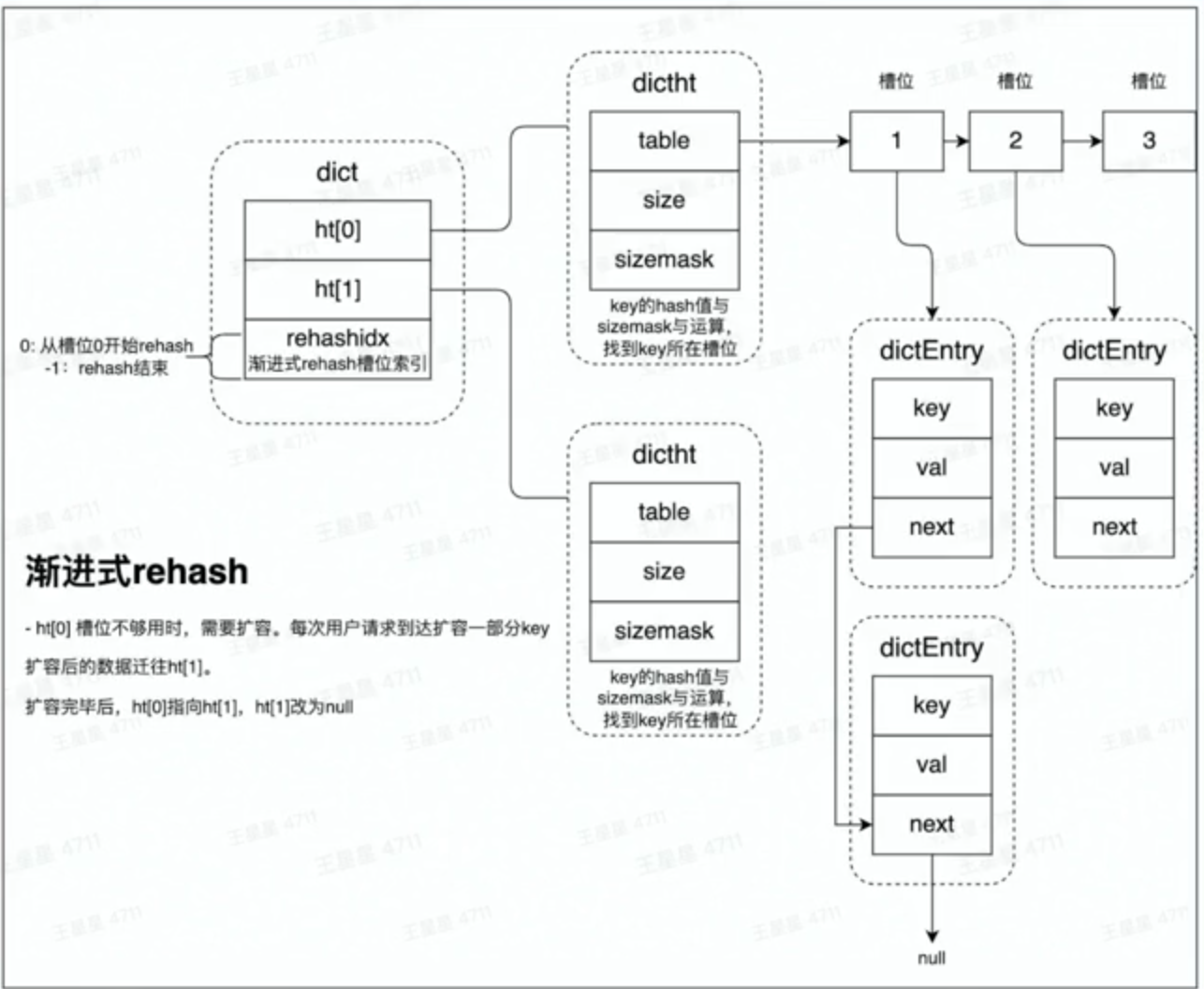
Redis需要提供高性能和高可靠的服务,在面临大量Hash槽位不足而需要扩容的情况下,Redis提供了渐进式rehash的解决方案。
如果Hash的槽位不足,我们需要创建一个新的Hash表,暂停用户响应并将原始hash表的数据迁移到新的hash表中,难以避免造成的长时间的拥堵。
渐进式rehash的思路是将迁移的时间成本分摊到每次用户访问中。具体而言,每一次用户访问都会将访问到的数据迁移到新的Hash表中,但是不启用,依旧访问原始的Hash表,在经过足够长的时间,原始Hash表中的数据便会迁移到新的Hash表中,这样就完成了无感的迁移。
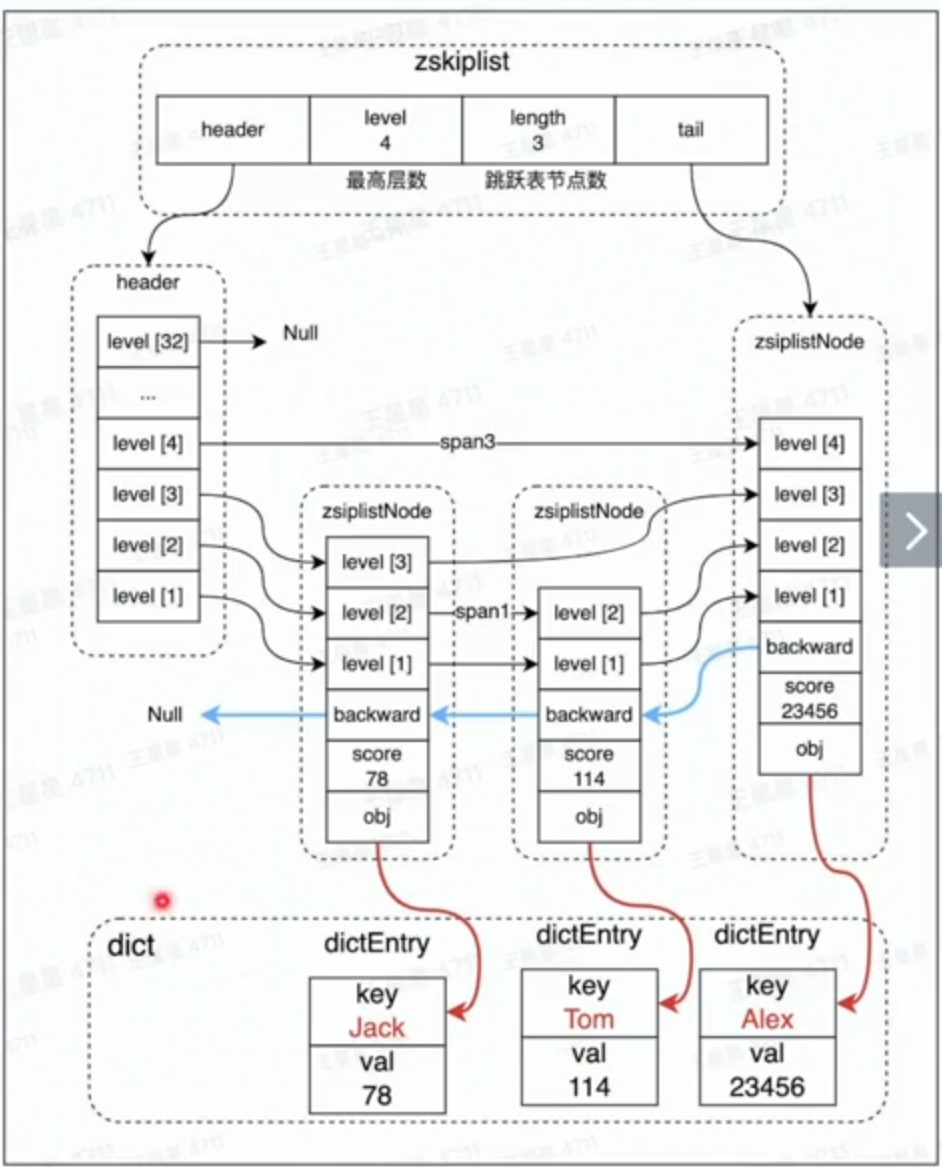
Zset
Zset是Redis提供的有序集合(Sorted Set) , 通过增加一个关联分数(Score)来实现对元素的排序,其主要用途非常广,如:
-
动态排行榜
-
延迟队列:使用score来存储任务执行的时间戳
Zset的底层数据结构基于跳表和Hash
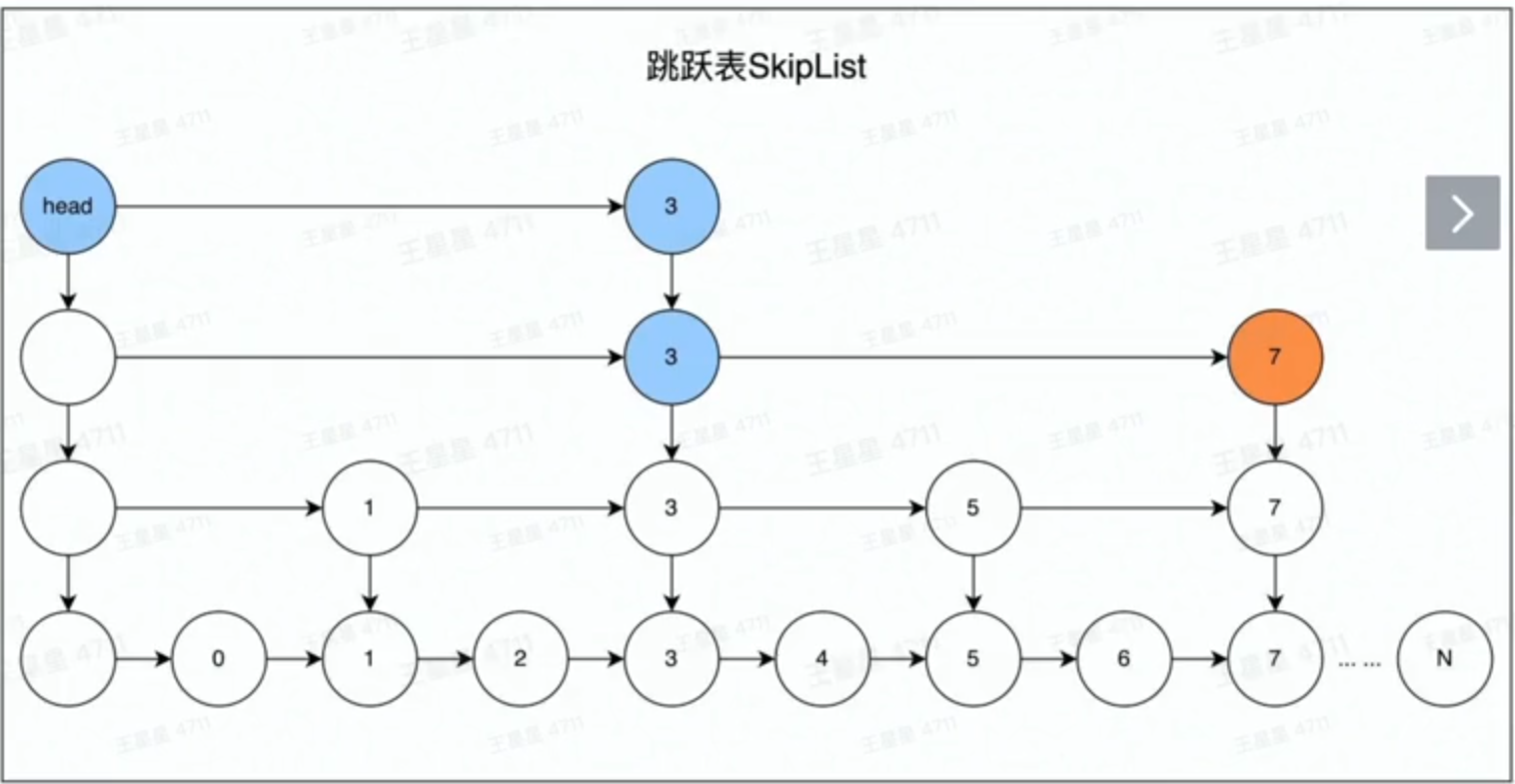
链表在修改操作上有极高的效率,但是在查询上的时间复杂度为, 而跳表 则通过多条不同的跳跃路径来加速查询。
在Zset中,每个元素的score存储在跳表中, 增删改查的时间复杂度都非常低。此外,为了快速定位到每个元素的score,Zset通过hash维护了元素到score的映射。
Redis持久化策略
Redis是一个基于内存的数据库,可能会导致数据丢失,因此需要通过持久化来将数据存储数据库。
AOF增量文件
AOF是一种增量的持久化方法。通过将操作追加到文件中来实现持久化,但是由于是文本形式的存储方式,占用空间会更大。
为了减少AOF文件的空间,Redis又采用定期rewrite的方法来重写备份的操作指令。
RDB全量文件
RDB是一种全量的持久化方法。RDB通过周期性地将数据保存到磁盘,其可以通过压缩的方法来大幅减少备份文件空间。
Redis常见注意事项
大Key、热Key
大Key的定义:
| 数据类型 | 大Key标准 |
| ------------------------------------ | ---------------------------------------------------- |
| String类型 | value的字节数大于10KB即为大Key |
| Hash/Set/Zset/list等复杂数据类型结构 | 元素个数大于5000个或者总value字节数大于10MB即为大Key |
因此,大Key会导致如下问题:
-
读取成本很高
-
容易导致慢查询(过期删除)
-
主从复制异常,服务阻塞,无法正常相应请求,请求超时报错
为了解决大Key问题,有两种实现思路:
-
大Key压缩:使用压缩方法(gzip)
-
大Key拆小Key:如果无法将大Key的value压缩,就只能尽量把大Key的value拆解成多个小的value;
-
集合类的结构hash、list、set、zset进行大Key拆成小Key,可以使用Hash取余来决定放在哪个key中
- 还有个独特的方法冷热分离,如榜单列表,银行账户历史账单,用户不大可能会查看全部数据,只会查询近期数据,那么Redis只缓存近期数据,全部数据走db,这样就避免了大key问题;
-
热Key的定义:
用户访问某个Key的QPS非常高,导致Server实例出现CPU突增的情况,难以应对全部请求。
慢查询
缓存穿透、缓存雪崩
-
缓存穿透:热点数据查询绕过了缓存,直接打向了db
-
缓存空值:如果查询一个不存在的数据,则缓存一个空值
-
布隆过滤器:通过bloom filter算法来存储合法key,得益于算法的超高压缩率,只需占用极小的空间就能存储大量key值
-
-
缓存雪崩:大量的缓存同时过期
- 分散过期时间
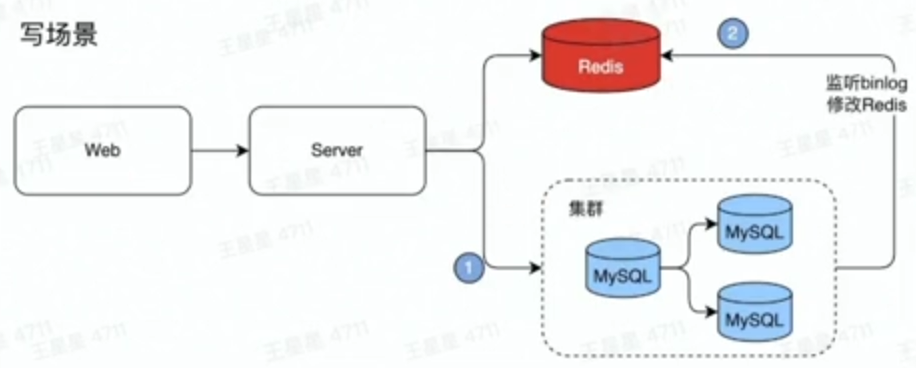
写场景下Redis的缓存一致性
Redis常见使用案例
连续签到
日常签到是很多APP增加日活的一种手段,用户连续签到就能获得一定的奖励,如果中间断签就会导致签到日期归0.
我们可以通过在Redis中设置用户-签到天数这样的key-value来保存用户的签到日期,同时通过Redis提供的过期时间能力来实现连续签到,比如设置为24h过期,那么24h之后key-value将会被清理,导致签到次数归0.
消息通知
使用到QuickList,另外一个解决方案是pub-sub,但是这里以list介绍
计数
使用了Hash,pipe管道来减少操作次数
排行榜
Zset
限流
对于单个用户不能过度请求接口,限制每秒的请求小于10次。key设置为req_limit_timestamp
分布式锁
由于Redis是单线程的优良特性,所以非常容易实现分布式锁。setnx命令
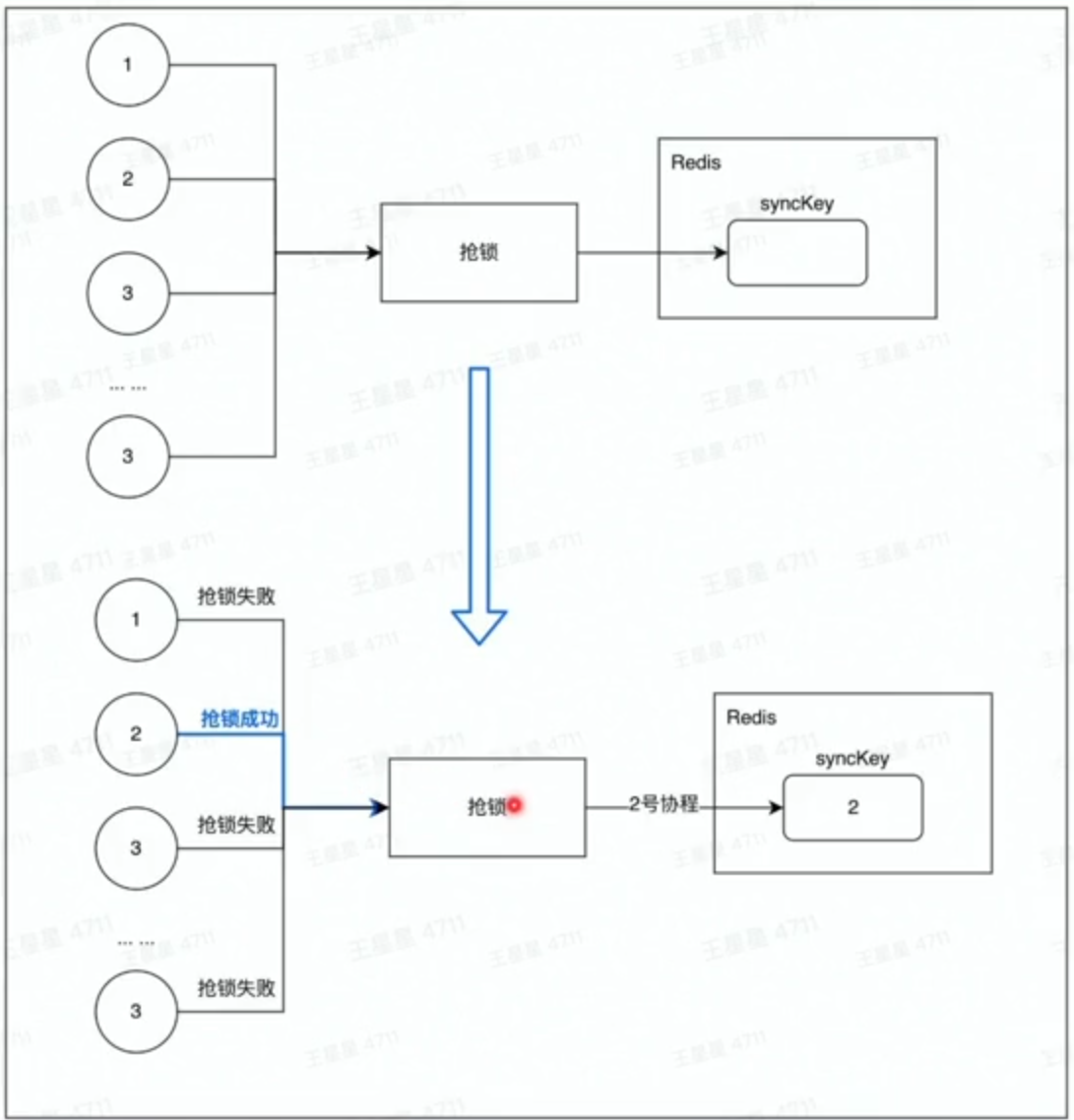
Redis的setnx提供的分布式锁能力也有很多缺点:
-
业务超时解锁,导致并发问题。业务执行时间超过解锁时间
-
redis主备切换临界点问题。主备切换后,A持有的锁还未同步到新的主节点时,B可在新的主节点获得锁
-
redis集群脑裂,导致出现多个主节点